随着科技的发展,人类越来越善于制造“假象”。
想在社交网络里人见人爱花见花开?
不用再像以前一样,当窗补唇蜜,对镜画卡姿兰,粉妆玉砌后才敢自拍发网上...

现在,只需对着自拍照发动亚洲四大邪术之一——PS。
精修细调后便可得到姣好的脸蛋,一巴掌都能打出半斤玻尿酸!

每次看到这些“妈问谁”的自拍厂长都不禁感叹——
这世间还有“真相”吗?
答案是肯定的,但以后就不一定了。。。
因为那些科技巨头们也开始帮着“造假”了!

小编不久前给你们介绍过英伟达那逆天的图像造假技术。
它可以根据已有的图像来创造出新的图像,无论照片还是视频!
当时它的技术可以实现三种变化——
第一种:颠倒黑白
将白天变换为黑夜,还会自动脑补上车灯路灯等细节,看得出PS痕迹么~

第二种:颠倒四季
将冬天变换为夏天,不仅雪地变草地,光秃秃的树枝也脑补出了茂盛的叶子,这特效可不止五毛呢~

第三种:颠倒物种
将喵星人变换成其他动物,而且可以只改变外形,不改变原本的姿态和背景,基因突变也不过如此~

而现在,英伟达通过与MIT的合作,将这种“造假”技术又带到了新的高度。
原来要想创造出新的图像你得先提供完整的素材,该有的细节还是得有...

而新的技术就不用那么讲究了,就算只有一个大体的轮廓它也能“无中生有”。
比如给它一个啥也看不清的动态地图,你就可以获得一段跟现实世界相仿的视频了。

你没有看错,街景里的道路、车辆、建筑、树木全是它脑补出来的!
如果不满意还可以单独把路边的建筑变成树木...

或者把树木变成建筑...

感觉很多电影的场景都不用实地拍了,全都能靠脑补!
不过风景可以无中生有,人呢?
嘿嘿~看到右边那个小姐姐了吗——

她就是根据左边的素描草图创造出来!
同样是给一个简单的轮廓,英伟达的算法就能把人的脸型、发型、五官、首饰、甚至连背景都脑补得清清楚楚。

而且跟上面的街景一样,你可以对视频里的某个部分进行单独变换。
换个发色换个肤色都妥妥的,感觉以后拍小电影也不用真人上阵了呢~


看到这里是不是觉得我们活在了假的世界?

那么如此高明的造假技术是怎么实现的呢?
本着“科学严谨”的态度,厂长先来一段又臭又长的科普——
人工智能通过生成对抗网络(Generative Adversarial Network,简称 GAN)来学习。这个网络由一个生成网络和判别网络组成,生成网络的任务是选取一个图像,然后尽量把它改造成目标图像交给判别网络。由于判别网络里事先输入了目标图像,所以它就会对生成网络生成的图像进行检验。两个网络不断对抗、改进,最后的目的是让生成网络造出一张连判别网络也分不出来的照片或视频。看完后是不是觉得...

没事,为了让你们能跟上时代的步伐,厂长呕心沥血做了张浅显的说明图。
左边的整容医院代表生成网络,它想把各种歪瓜裂枣整成女神;
右边的喝X群众代表判别网络,它想检验医院整出的女神是否合格。
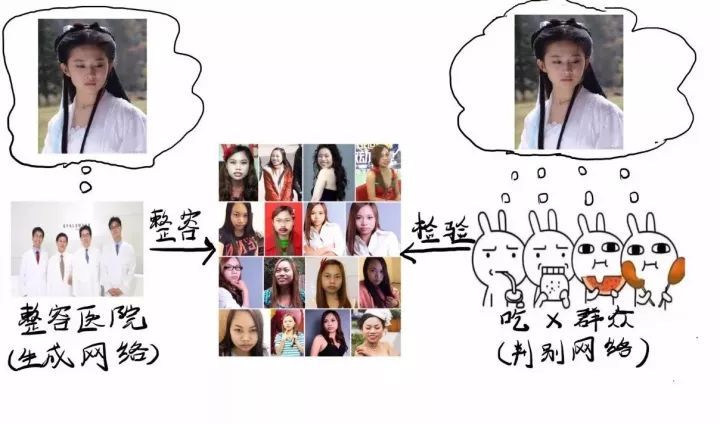
而这整个系统就叫做对抗网络(GAN)。
如图所见,当我告诉它“女神”就是刘亦菲这个样子后...医院拼命整容,群众拼命检验!
就这么互相对抗着,医院的整容技术不断升级,最后终于整出了个让群众也分不出真假的刘亦菲,取得胜利!

这个对抗网络的牛逼之处在于——
以前的人工智能需要有人来帮它标记不同,然后再根据这些标记来学习新技能,但这个系统不用,通过互相对抗就能学习~

除了能脑补出各种场景和人脸,它还可以根据人体模型的动作来生成同步的真人视频!

此外生成的图像清晰度较去年也有很大提升。
去年是这种糊成狗的画质...

现在就好多了,没有异常的闪动和模糊~

据了解,这种新技术训练出来的模型目前可以生成长达30秒的2K街景视频!
不怕放大吗敢做这么高清...看来老黄还是对自家的造假技术很有自信~

不过这种技术的出现对我们吃瓜群众来说还是挺瘆人的...
记得之前Adobe还推出过一种可以修改录音的软件——Project VoCo。
它可以根据一个人说话的录音,合成几乎以假乱真的任意话语!
照片可以造假
视频可以造假
声音可以造假
...
以后还有什么可以信的?
版权声明:CosMeDna所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系删除!
本文链接://www.cosmedna.com/article/743473799.html